3.1 MNIST
사이킷런에서 제공하는 헬퍼 함수를 사용해 데이터셋을 내려받을 수 있음.
- fetch_* 함수 (ex. fetch_openml()) : 실전 데이터 셋을 다운로드하는 함수
- load_* 함수 : 소규모 데이터셋 로드하기 위한 함수
- make_* 함수 : 가짜 데이터셋을 생성하기 위한 함수
이미지 하나 출력해서 확인해보기
import matplotlib.pyplot as plt
def plot_digit(image_data):
image = image_data.reshape(28, 28) 28 X 28 배열 사이즈
plt.imshow(image, cmap="binary") 흑백 설정
plt.axis("off")
some_digit = X[0]
plot_digit(some_digit)
save_fig("some_digit_plot")
plt.show()📌 데이터 자세히 조사 전에 항상 테스트 세트를 만들고 따로 떼어놓기

3.2 이진분류기 훈련
이진분류기 : 두개의 클래스를 구분할 수 있음
위의 숫자를 경사하강법 분류기를 이용한 분류기로 5인지 아닌지 알아보는 코드
y_train_5 = (y_train == 5) # 5는 True고, 다른 숫자는 모두 False
y_test_5 = (y_test == 5)
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
sgd_clf.predict([some_digit])결과는
array([ True])5를 나타낸다고 추측했음.
3.3 성능 측정
3.3.1 교차 검증을 사용한 정확도 측정
k-폴드 교차 검증 : 훈련 세트를 k개의 폴드로 나누고, 평가를 위해 매번 다른 폴드를 떼어놓고 모델을 k번 훈련(참고링크)
📌 불균형한 데이터셋을 다룰 때 분류기의 성능을 평가하는 더 좋은 방법은 오차 행렬을 조사하는 것이다.
3.3.2 오차 행렬
- 오차 행렬 : 모든 A/B쌍에 대해 클래스 A의 샘플이 클래스 B로 분류된 횟수를 세는 것
- 오차 행렬의 행 : 실제 클래스
- 오차 행렬의 열 : 예측한 클래스
- 완벽한 분류기인 경우에는 오차 행렬의 주대각선만 0이 아닌 값이 됨.
3.3.3 정밀도와 재현율
정밀도 : 양성 예측의 정확도

재현율 : 분류기가 정확하게 감지한 양성 샘플의 비율


F1점수 : 정밀도와 재현율의 조화 평균

3.3.4 정밀도/재현율 트레이드오프
정밀도/재현율 트레이드오프: 정밀도를 올리면 재현율이 줄고 그 반대도 마찬기지 인 것
사이킷런에서 임곗값을 직접 지정할 수는 없지만 예측에 사용한 점수는 확인 가능, 이 점수를 기반으로 원하는 임곗값을 정해 예측을 만들 수 있음!
적절한 임곗값 구하는 법
- 훈련 세트에 있는 모든 샘플의 점수 구하기 (결정점수)
- 맷플롭릿을 이용해 임곗값의 함수로 정밀도 재현율 그릴 수 있음
plt.figure(figsize=(8, 4)) # 추가 코드
plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2)
plt.plot(thresholds, recalls[:-1], "g-", label="Recall", linewidth=2)
plt.vlines(threshold, 0, 1.0, "k", "dotted", label="threshold")
# 추가 코드 – 그림 3–5를 그리고 저장합니다
idx = (thresholds >= threshold).argmax() # 첫 번째 index ≥ threshold
plt.plot(thresholds[idx], precisions[idx], "bo")
plt.plot(thresholds[idx], recalls[idx], "go")
plt.axis([-50000, 50000, 0, 1])
plt.grid()
plt.xlabel("Threshold")
plt.legend(loc="center right")
save_fig("precision_recall_vs_threshold_plot")
plt.show()

재현율의 80 퍼센트 근처에서 정밀도가 급격히 하강함.
이 하강점 직전을 정밀도/재현율 트레이드오프로 선택하는 것이 좋음.
3.3.5 ROC 곡선
ROC 곡선 : 거짓 양성 비율에 대한 진짜 양성 비율의 곡선. 양성으로 잘못 분류된 음성 샘플의 비율 의미
1에서 음성 샘플의 비율인 진짜 음성 비율을 뺀 값.
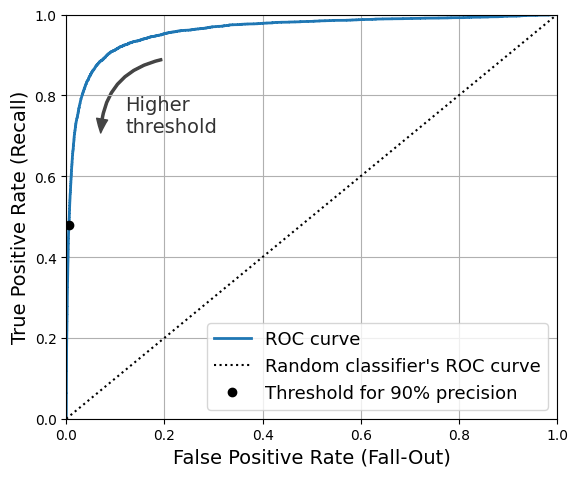
재현율이 높을수록 분류기가 만드는 거짓 양성 비율이 늘어난다.
점선은 완전한 랜덤 분류기의 ROC 곡선을 의미하며 좋은 분류기는 이 점선에서 최대한 멀리 떨어져 있어야 한다.
❗ 랜덤 분류기 : 훈련 데이터의 클래스 비율을 따라 랜덤으로 예측하는 것
3.4 다중분류
다중 분류기는 둘 이상의 클래스를 구별할 수 있다.
OvO 전략 : 각 숫자의 조합마다 이진 분류기를 훈련시키는 것 (서포트벡터머신에서 선호)
OvR or OvA 전략 : 이미지를 분류할 때 각 분류기의 결정 점수 중 가장 높은 것을 클래스로 선택하는 것
3.5 오류 분석
오차 행렬을 그래프로 나타내면 어디에서 오류가 많이 났는지 확인 하기 쉬워진다.
대부분의 이미지가 주대각선에 위치해있다면 이는 이미지가 올바르게 분류됨을 의미한다.
❗모델이 5 영역에서 더 많은 오류를 범했거나 데이터 집합에 다른 숫자보다 5 영역이 적을 때 정규화하는 것이 중요.
"normalize = true"
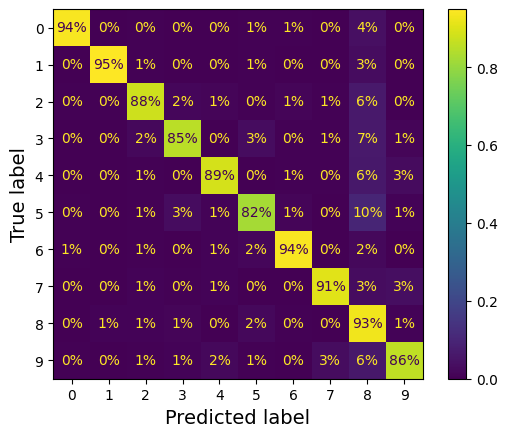
올바른 예측에 대한 가중치를 0으로 설정하면 오류를 더 알아보기 쉬워진다.
normalize = "pred" -> 오차 행렬을 열 단위로 정규화 할 수 있다.
📌 분류기는 이미지의 위치나 회전 방향에 매우 민감함.
📌 데이터 증식 : 훈련 이미지를 약간 이동시키거나 회전된 변형 이미지로 훈련 집합을 보강하는 것
3.6 다중 레이블 분류
다중 레이블 분류 : 여러 개의 이진 꼬리표를 출력하는 분류 시스템
KNeighborsClassifier - 다중 타깃 배열을 사용해 훈련시킴
다중 레이블 분류기를 평가하는 방법
1. F1 점수를 구하고 간단하게 평균 점수를 계산하는 것
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
y_train_large = (y_train >= '7')
y_train_odd = (y_train.astype('int8') % 2 == 1)
y_multilabel = np.c_[y_train_large, y_train_odd]
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
레이블에 클래스의 지지도를 가중치로 주는 것 - average = "weighted"
❗ 다중 레이블 분류를 지원하지 않는 분류기를 사용하는 경우 - 레이블당 하나의 모델을 학습
3.7 다중 출력 분류
다중 출력 다중 클래스 분류(다중 출력 분류) : 다중 레이블 분류에서 한 레이블이 다중 클래스가 될 수 있도록 일반화한 것
'소프트웨어 > 머신러닝' 카테고리의 다른 글
| 머신러닝 7주차 (0) | 2025.03.12 |
|---|---|
| 머신러닝 6주차 (1) | 2025.03.05 |
| 머신러닝 4주차 - 앙상블 학습과 랜덤 포레스트 (0) | 2025.02.10 |
| 머신러닝 3주차 - 서포트 벡터 머신 , 결정트리 (0) | 2025.02.04 |
| 머신러닝 2주차 - 모델 훈련 (0) | 2025.01.25 |



