💡 사물을 감지하거나 음성을 인식하는 일 등을 인간이 쉽게 할 수 있는 이유는?
- > 사람의 지각이 주로 의식의 영역 밖, 즉 뇌의 특별한 시각, 청각, 그리고 다른 감각 기관에서 일어난다는 사실
시각피질 구조
시각 피질 안의 많은 뉴런이 작은 국부 수용장을 가짐 -> 뉴런들이 시야의 일부 범위 안에 있는 시각 자극에만 반응한다는 뜻
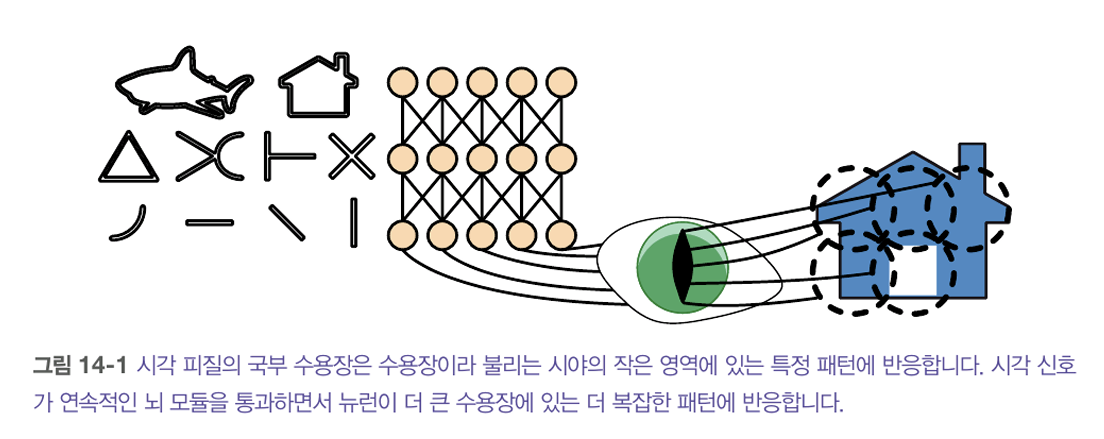
시각 피질 연구에서 합성곱 신경망으로 점진적으로 진화.
LeNet-5 구조가 생김. 이 구조는 합성곱 층과 풀링 층이라는 새로운 구성 요소가 포함되어있음.
합성곱 층

- CNN의 가장 중요한 구성 요소
- 첫 번째 합성곱 층의 뉴런은 합성곱 층 뉴런의 수용장 안에 있는 픽셀에만 연결
- 두 번째 합성곱 층에 있는 각 뉴런은 첫 번째 층의 작은 사각 영역 안에 위치한 뉴런에 연결
- 이런 구조는 네트워크가 첫 번째 은닉 층에서는 작은 저수준 특성에 집중하고, 그 다음 은닉 층에서는 더 큰 고수준 특성으로 조합해 나가도록 도와줌.

- 위의 사진처럼 수용장 사이에 간격을 두어 큰 입력 층을 훨씬 작은 층에 연결하는 것도 가능.
- 이렇게 하면 모델의 계산 복잡도가 줄어든다.
- 스트라이드 : 한 수용장과 다음 수용장 사이의 수평 또는 수직 방향 스텝 크기
필터

뉴런의 가중치는 수용장 크기의 작은 이미지로 표현
층의 전체 뉴런에 적용된 하나의 필터는 하나의 특성 맵을 만들고, 이 맵은 필터를 가장 크게 활성화시키는 이미지의 영역을 강조한다.
여러 가지 특성 맵 쌓기
- 실제 합성곱 층은 여러 가지 필터를 가지고 필터마다 하나의 특성 맵을 출력하므로 3D로 표현하는 것이 더 정확하다.
- 각 특성 맵의 픽셀은 하나의 뉴런에 해당하고 하나의 특성 맵 안에서는 모든 뉴런이 같은 파라미터를 공유하지만, 다른 특성 맵에 있는 뉴런은 다른 파라미터를 사용한다.
- ⭐하나의 합성곱 층이 입력에 여러 필터를 동시에 적용하여 입력에 있는 여러 특성을 감지할 수 있다.
- 입력 이미지는 컬러 채널마다 하나씩 여러 서브 층으로 구성되기도 한다.

메모리 요구 사항
- CNN에 관련된 또 하나의 문제는 합성곱 층이 많은 양의 RAM을 필요로 한다
- ❗추론을 할 때 하나의 층이 점유하고 있는 RAM은 다음 층의 계산이 완료되자마자 해제될 수 있다. 그러므로 연속된 두 개의 층에서 필요로 하는 만큼의 RAM만 가지고 있으면 된다. 하지만 훈련하는 동안에는 정방향에서 계산했던 모든 값이 역방향을 위해 보전되어야한다. 그래서 각 층에서 필요한 RAM 양의 전체 합만큼 RAM이 필요하다.
풀링 층
- 목적 : 게산량과 메모리 사용량, 파라미터 수를 줄이기 위해 입력 이미지의 부표본을 만드는 것
- 풀링 층의 각 뉴런은 이전 층의 작은 사각 영역의 수용장 안에 있는 뉴런의 출력과 연결 되어있음.
- 크기, 스트라이드, 패딩 유형을 지정해야 함.
- 풀링 뉴런은 가중치가 없음. 즉 최대나 평균 같은 합산 함수를 사용해 입력값을 더하는 것이 전부이다.
- 널리 사용되는 풀링 층 : 최대 풀링 층

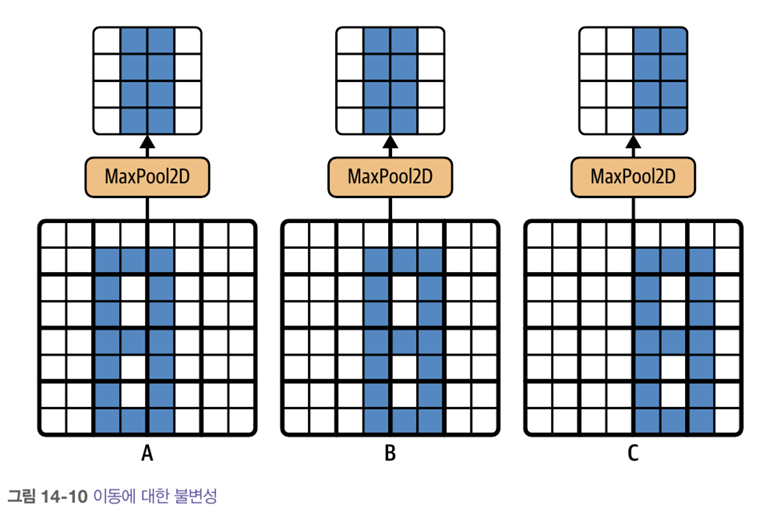
- 최대 풀링은 작은 변화에도 일정 수준의 불변성을 만들어줌.
- 이미지 A와 B에서 최대 풀링 층의 출력은 동일하다. 이것이 이동 불변성이다.
- CNN에서 몇 개 층마다 최대 풀링 층을 추가하면 전체적으로 일정 수준의 이동 불변성을 얻을 수 있다.
- 또한 최대 풀링은 회전과 확대, 축소에 대해 약간의 불변성을 제공한다.
- 최대 풀링의 단점은 매우 파괴적이라는 것이다...
- 최대 풀링은 의미없는 없는 것은 모두 제거하고 가장 큰 특징만 유지함. 그렇기에 다음 층이 조금 더 명확한 신호로 작업할 수 있음.
- 평균 풀링보다 강력한 이동 불변성을 제공하고 연산 비용이 조금 덜 든다.

전역 평균 풀링 층
- 각 특성 맵의 평균을 계산한다. = 각 샘플의 특성 맵마다 하나의 숫자를 출력한다는 의미
- 이는 출력 층 직전에 유용하게 쓰인다.
CNN 구조

- 전형적인 CNN 구조는 합성곱 층을 몇 개 쌓고, 그 다음에 풀링 층을 쌓고, 그 다음에 또 합성곱 층을 몇 개 더 쌓고, 그 다음에 다시 풀링 층을 쌓는 식이다.
- 네트워크를 통과하여 진행할수록 이미지는 점점 작아지지만 합성곱 층 때문에 일반적으로 점점 더 깊어진다.
- 맨 위층에는 몇 개의 완전 연결 층으로 구성된 일반적인 피드포워드 신경망이 추가되고 마지막 층에서 예측을 출력한다.
LeNet-5

- 가장 널리 알려진 CNN 구조
- 이 모델은 패션 MNIST구조와 매우 비슷
- 합성곱 층과 풀링 층을 쌓고 밀집 층이 뒤따름.
- 최신 분류 CNN과 가장 크게 차이나는 점은 활성화 함수일 것이다.
- ReLU를 사용하고 RBF 대신에 소프트맥스를 사용
AlexNet

- 더 크고 깊을 뿐만 아니라 LeNet-5와 비슷하다.
- 처음으로 합성곱 층 위에 풀링층을 쌓지 않고 바로 합성곱 층끼리 쌓았음.
- 과대적합을 줄이기 위해 저자들은 두 가지 규제 기법을 사용했음.
- 훈련하는 동안 F9과 F10의 출력에 드롭아웃을 50% 비율로 적용
- 훈련 이미지를 랜덤하게 여러 간격으로 이동하거나 수평으로 뒤집고 조명을 바꾸는 식으로 데이터 증식을 수행
- C1과 C3층의 ReLU 단계 후에 바로 LRN이라 부르는 경쟁적인 정규화 단계를 사용
- 가장 강하게 활성화된 뉴런이 다른 특성 맵에 있는 같은 위치의 뉴런을 억제함.
데이터 증식
- 진짜 같은 훈련 샘플을 인공적으로 생성하여 훈련 세트의 크기를 늘림.
- 과대적합을 줄이므로 규제 기법으로 사용할 수 있음.
- 생성된 샘플은 가능한 진짜에 가까워야함.
- 이상적으로는 증식된 훈련 세트에서 이미지를 뽑았을 때 증식된 것인지 아닌지를 구분 할 수 없어야 함
GoogLeNet
- 인셉션 모듈이라는 서브 네트워크를 가지고 있어서 GoogLeNet이 이전의 구조보다 훨씬 효과적으로 파라미터를 사용
- 네트워크가 이전 CNN보다 훨씬 깊음.
- 모든 층은 스트라이드 1과 "same" 패딩을 사용하므로 출력의 높이와 너비가 모두 입력과 같음.
- 이렇게 하면 모든 출력을 깊이 연결 층에서 깊이 방향으로 연결할 수 있음.

💡 왜 인셉션 모듈이 1 X 1 커널의 합성곱 층을 가질까? 이 층의 목적은 ?
- 깊이 차원을 따라 놓인 패턴을 잡을 수 있음.
- 병목 층의 역할을 담당함. 연산 비요ㅛㅇ과 파라미터 개수를 줄여 훈련 속도를 높이고 일반화 성능을 향상
- 더 복잡한 패턴을 감지할 수 있는 한 개의 강력한 합성곱 층처럼 작동
GoogLeNet의 실제 구조

- 네트워크를 하나로 길게 쌓은 구조
- 모든 합성곱 층은 ReLU 활성화 함수를 사용
14-15 설명
- 초기 두 개의 층에서 계산량을 줄이기 위해 이미지의 높이와 너비를 4배씩 축소 (면적 기준 16배 감소). 첫 번째 층에서는 7×7 크기의 커널을 사용하여 정보를 최대한 유지함.
- LRN(Local Response Normalization) 층을 사용하여 이전 층에서 다양한 특성을 학습하도록 구성. 이후 두 개의 합성곱 층 중 첫 번째 층은 병목층 역할을 수행.
- 다시 한 번 LRN 층을 적용하여 이전 층이 다양한 패턴을 학습하도록 만듦.
- 최대 풀링(Max Pooling) 층을 사용하여 계산 속도를 높이기 위해 이미지의 높이와 너비를 2배씩 줄임.
- 9개의 인셉션 모듈을 연속적으로 연결하여 차원 감소 및 속도 향상을 도모.
- 전역 평균 풀링(Global Average Pooling) 층을 사용하여 각 특성 맵의 평균값을 출력. 이 과정에서 공간 방향 정보가 손실되지만, 분류 작업에서는 문제가 되지 않음.
- 마지막으로 드롭아웃(Dropout) 층을 적용한 후, 1,000개 클래스에 대한 유닛과 Softmax 활성화 함수를 사용하여 최종 확률값을 출력.
VGGNet
- 2개 또는 3개의 합성곱 층 뒤에 풀링 층이 나오고 다시 2개 또는 3개의 합성곱 층과 풀링 층이 등장하는 식
- 마지막 밀집 네트워크 2개의 은닉 층과 출력 층으로 이루어짐
- VGGNet은 많은 개수의 필터를 사용하지만 3X3 필터만 사용
ResNet
- 더 적은 파라미터를 사용해 점점 더 깊은 네트워크로 컴퓨터 비전 모델을 구서ㅓㅇ하는 일반적인 트렌드를 만듦.
- 이런 깊은 네트워크를 훈련시킬 수 있는 핵심 요소는 스킵 연결
- 어떤 층에 주입되는 신호가 상위 층의 출력에도 더해짐.
- 만약 입력 x를 네트워크의 출력에 더한다면 네트워크는 h(x) 대신 f(x) = h(x) - x를 학습, 이를 잔차 학습이라 함.

- 신경망을 초기화 할 때는 가중치가 0에 가깝기 때문에 네트워크도 0에 가까운 값을 출력.
- 스킵 연결을 추가하면 이 네트워크는 입력과 같은 값을 출력
- 초기에는 항등 함수를 모델링

- 스킵 연결 덕분에 입력 신호가 전체 네트워크에 손쉽게 영향을 미치게 됨.
- 심층 잔차 네트워크는 스킵 연결을 가진 작은 신경망이 잔차 유닛을 쌓은 것을 볼 수 있음.
- 이 구조는 GoogLeNet과 똑같이 시작하고 종료함. 다만 중간에 단순한 잔차 유닛을 매우 깊게 쌓은 것 뿐이다.
Xception

- GoogLeNet과 ResNet의 아이디어를 합쳤지만 인셉션 모듈은 깊이별 분리 합성곱 층이라는 특별한 층으로 대체
- 분리 합성곱 층은 입력 채널마다 하나의 공간 필터만 가지기 때문에 입력 층과 같이 채널이 너무 적은 층 다음에 사용하는 것을 피해야 함.
- Xception 구조는 2개의 일반 합성곱 층으로 시작
- 이 구조의 나머지는 분리 합성곱만 사용
- 거기에 몇 개의 최대 풀링 층과 전형적인 마지막 층들을 사용
- 인셉션 모듈은 1x1 필터를 사용한 합성곱 층을 포함
- 이 층은 채널 사이 패턴만 감지
- 하지만 이 위에 놓인 합성곱 층은 공간과 채널 패턴을 모두 감지하는 일반적인 합성곱 층
- 따라서 인셉션 모듈을 일반 합성곱 층과 분리 합성곱 층의 중간 형태로 생각할 수 있음.
SENet
- 인셉션 네트워크와 ResNet을 확장한 버전을 각각 SE-Inception과 SE-ResNet이라고 부름
- SENet은 원래 구조에 있는 모든 인셉션 모듈이나 모든 잔차 유닛에 SE 블록이라는 작은 신경망을 추가하여 성능을 향상

- SE 블록이 추가된 부분의 유닛의 출력을 깊이 차원에 초점을 맞추어 분석함.
- 어떤 특성이 일반적으로 동시에 가장 크게 활성화되는지 학습한 다음, 이 정보를 사용하여 특성 맵을 보정

- 하나의 SE 블록은 3개의 층으로 구성
- 전역 평균 풀링 층과 ReLU 활성화 함수를 사용하는 밀집 은닉 층, 시그모이드 활성화 함수를 사용하는 밀집 출력 층

주목할만한 다른 구조들
- ResNeXt: ResNet을 확장한 구조로, 그룹화된 병렬 합성곱(Grouped Convolution) 방식을 사용해 성능을 향상시키면서도 계산량을 효율적으로 유지하는 네트워크.
- DenseNet: 각 레이어가 이전 모든 레이어의 출력을 직접 받아들이는 연결(Dense Connectivity) 방식을 사용하여 파라미터 수를 줄이고 특징 전달을 극대화하는 네트워크.
- MobileNet: 깊이별 분리 합성곱(Depthwise Separable Convolution)을 활용하여 연산량을 줄이고 모바일 및 임베디드 환경에서 높은 효율성을 가지는 경량 네트워크.
- CSPNet: 네트워크의 특성 맵을 부분적으로 분할하여 처리한 후 다시 합치는 방식으로 연산량을 줄이고 성능을 향상시키는 Cross Stage Partial Network 구조.
- EfficientNet: 모델 크기, 해상도, 깊이를 균형 있게 조정하는 복합 계수(Compound Scaling)를 적용하여 성능을 극대화하면서도 연산량을 최소화한 네트워크.
올바른 CNN 구조 선택
- 정확도, 모델 크기, CPU의 추론 속도, GPU에서 추론 속도 등에 따라 달라짐.
- ❗모델이 클수록 일반적으로 정확도가 높지만 항상 그렇지는 않습니다.

객체 탐지
- 객체 탐지 : 하나의 이미지에서 여러 물체를 분류하고 위치를 추정하는 작업
- 이 CNN은 일반적으로 클래스 확률과 바운딩 박스 외에도 객체성 점수를 예측하도록 훈련된다.
- 객체성 점수 : 이미지의 중앙부에 실제 객체가 있는지에 대한 추정 확률
- 객체성 점수 값은 이진 분류 출력이므로 하나의 유닛과 시그모이드 활성화 함수를 가진 밀집 출력 층을 사용하고 이진 크로스 엔트로피 손실로 훈련하여 만들 수 있음.
NMS : 불필요한 바운딩 박스를 제거하기 위해 진행하는 사후 처리 방법
- 먼저 객체성 점수가 일정 임곗값보다 낮은 바운딩 박스를 모두 삭제한다. CNN이 해당 위치에 객체가 없다고 믿기 때문에 이런 바운딩 박스는 쓸모가 없다.
- 남은 바운딩 박스에서 객체성 점수가 가장 높은 바운딩 박스를 찾고 이 박스와 많이 중첩된 다른 바운딩 박스를 모두 제거한다.
- 더는 제거할 바운딩 박스가 없을때까지 2.를 반복한다.
- 이런 객체 탐지 방식은 꽤 잘 작동하지만 CNN을 여러 번 실행시켜야 하므로 많이 느리다.
- 완전 합성곱 신경망을 사용하면 CNN을 훨씬 바르게 이미지에 슬라이딩 시킬 수 있다.
완전 합성곱 신경망
- 네트워크의 역할 : 밀집 층은 특정 입력 크기를 기대하지만 합성곱 층은 어떤 크기의 이미지도 처리할 수 있음. FCN은 합성곱 층만 가지므로 어떤 크기의 이미지에서도 훈련하고 실행 할 수 있음
YOLO
- 빠르고 정확한 객체 탐지 구조
- 실시간으로 비디오에 적용할 수 있음.
- 객체 탐지를 한 번의 신경망 실행으로 수행하는 고속·고효율 실시간 객체 탐지 모델. 전체 이미지를 한 번에 처리하여 빠른 속도로 객체 위치와 클래스 예측이 가능함.
mAP : 객체 탐지에서 널리 사용되는 평가 지표
- 재현율에서의 최대 정밀도를 계산하는 것
- 그런 다음 이 최대 정밀도를 평균함. -> 이게 평균 정밀도(AP)
- 두 개 이상의 클래스가 있을 대 각 클래스에 대해 AP를 계산한 다음 평균 AP를 계산한 것이 mAP이다.
객체 추적
- 가장 널리 사용되는 객체 추적 시스템은 DeepSORT
- 고전적인 알고리즘과 딥러닝의 조합을 기반으로 함.
간단한 추적 과정 설명
- 객체가 일정한 속도로 움직인다고 가정, 칼만 필터를 사용해 이전에 감지된 객체의 가장 가능성이 높은 현재 위치를 추정합니다.
- 딥러닝 모델을 사용하여 새로운 탐지 결과와 기존 추적 객체 간의 유사성을 측정한다.
- 헝가리 알고리즘을 사용해 새로운 탐지 대상을 기존 추적 객체에 매핑한다. 이 알고리즘은 탐지된 결과와 추적 객체의 예측 위치 사이의 거ㅓ리를 최소화하는 동시에 외관상의 불일치를 최소화하는 매핑 조합을 효율적으로 찾음.
시맨틱 분할
각 픽셀은 픽셀이 속한 객체의 클래스로 분류된다.
CNN은 이미지의 왼쪽 아래 어딘가에 사람이 있단 것은 알 수 있지만 그보다 더 정확히 알지는 못한다.

여기서 마지막 층이 입력 이미지보다 32배나 작은 특성 맵을 출력한다. 따라서 해상도를 32배 로 늘리는 업샘플링 층을 하나 추가한다.
여기서는 전치 합성곱 층을 사용했다.
💡전치 합성곱 층 : 기존 합성곱과 반대 방향으로 작동하여 작은 특성 맵을 더 큰 해상도로 복원하는 층. 주로 이미지 업샘플링에서 사용되며, 특징을 유지하면서도 해상도를 증가시키는 역할을 함.

- 업샘플링을 위해 전치 합성곱 층을 사용하는 것은 좋은 방법이지만 여전히 정확도가 떨어짐. 이를 개선하기 위해 아래쪽 층에서부터 스킵 연결을 추가한다.
초해상도
: 원본 이미지 크기보다 더 크게 업샘플링 하는 등 이미지의 해상도를 높이는 데 사용

초해상도 만드는 과정
- 2배 업샘플링
- 아래쪽 층의 출력을 더함
- 2배 업샘플링
- 더 아래쪽 층의 출력을 더함
- 8배 업샘플링
인스턴스 분할
- 각 물체를 구분하여 표시
- Mask R-CNN 구조는 각 바운딩 박스에 대해 픽셀 마스크를 추가로 생성하여 Faster R-CNN 모델을 확장
- 각 객체에 대해 일련의 추정 클래스 확률을 포함한 바운딩 박스를 얻을 수 있을 뿐만 아니라 바운딩 박스에서 객체에 속하는 픽셀을 찾아내는 픽셀 마스크도 얻을 수 있음.
'소프트웨어 > 머신러닝' 카테고리의 다른 글
| 머신러닝 6주차 (1) | 2025.03.05 |
|---|---|
| 머신러닝 4주차 - 앙상블 학습과 랜덤 포레스트 (0) | 2025.02.10 |
| 머신러닝 3주차 - 서포트 벡터 머신 , 결정트리 (0) | 2025.02.04 |
| 머신러닝 2주차 - 모델 훈련 (0) | 2025.01.25 |
| 머신러닝 1주차 - 분류 (0) | 2025.01.21 |



